博客实现 RSS 订阅能力全记录

我的个人网站 LRD.IM 从 2018 年元旦发布至今,已经持续维护 4 年了。从最开始根据一个网站模板替换图文,到现在全面的「自主研发」,这是我最骄傲的一款作品。接下来要开始尝试将我的博客内容输出成 RSS 源。
这篇博客不谈设计。写一点自己对互联网的初印象,将博客做成 RSS 源的原因,以及使用 RSSHub 将自己网站生成订阅源的过程。
吹吹水:我的互联网回忆录
对早期互联网的印象

家里 2005 年配置了台电脑,依稀记得那会儿互联网的潮流正好是从门户网站转换到「社会性网络」。
Discuz!、贴吧、QQ空间、开心网等等,都是 Web 2.0 的代表作,我「当年」也有高度参与到这些生态里面。那时候的互联网鼓励人们创造内容,强调互动和内容本身。而不像现在基于所谓的「算法」一直在投喂内容,网站上充斥着营销号、广告、对立、(甚至审查🤫)…
我记得以前网络上的内容是挺有趣的,因为都是自发的内容,感觉很真实。而现在在网上看到「有趣」的内容,却总感觉像是某个 MCN 机构生产出来的,所有内容都有目的,一直在包装、孵化,指向最后的变现…
所以正好我这位在 Web 2.0 时代背景下成长的网民,正好也有掌握了一些专业知识,于是乎就捣鼓出属于我的个人网站 LRD.IM,以及目前为止积累了 40 多篇的设计博客。一方面是想通过这些来积累自己的专业知识,另一方面是更想在互联网上留下自己的(且属于自己)的一些痕迹。
对 RSS 的执念

以前在 WordPress 搭建的博客、新闻资讯等网站总会有一个 RSS 订阅渠道,最初还没有了解过是什么意思,只是记住了有这个很不起眼的橙色的彩虹条纹的图标。
直到在大学了解到了一些信息获取来源方式和分类之后,才真正了解到 RSS 这个东西。很神奇的是它将内容进行重新格式化输出,将内容和从页面中分离出来,供读者在自己喜欢的第三方阅读器里接收新内容并阅读。
我还是挺认同这个概念的,即使它是 20 年前的产物。
分离原本的网页,意味着读者可以根据自己喜好在第三方阅读器上进行阅读,甚至自己捣鼓一个阅读器,而并非局限在原本网页管理者的设计中。
而第三方阅读器通常都会有新内容通知、已读未读标记、分类、标签等功能,这意味着读者能够拥有自己的一套信息获取方式,而不需要受到算法的介入,并能及时获得新内容的推送。
正好由于今年我的设计博客还上了不少公众号、周报的推荐,我察觉到拥有一个自己的内容推送服务迫在眉睫,而 RSS 订阅、邮件订阅都能满足这个需求,正好我就先将 RSS 订阅服务做起来先。

综上所述,我认同 RSS 的中立、纯粹、无算法介入,以及需要获取一个推送功能。所以,这时的我作为互联网内容生产者,是时候为自己的博客搭建一个 RSS 服务了!
实打实:将自己的网站生成 RSS 订阅源
预期
首先阐述下我的预期效果:
- 抓取到 Blog 页面里的所有博客,并能检测到内容变动(包括增删改);
- 将抓取的内容生成为 RSS 要求的格式,比如 XML;
- 更新内容时,在第三方阅读器中确保至少的时效性(不会延迟太久)和内容准确度(顺序不会错乱);
- 订阅链接用回自己的域名。
尝试一:第三方生成服务

于是乎我首先也试了几个做法,第一个是寄托于第三方的 RSS 生成服务。比如 Feed43、Feedburner、RSS.app。当时我是期望这些第三方服务能够满足上述的预期效果,自动抓取我发布的新博客生成为 RSS 文件。它们确实也做到了,但会各自有一些硬伤。
- Feed43:更新快,准确。但是免费版里生成的 Feed 里面会带有它们品牌的宣传,且国内访问速度一般;
- Feedburner:更新速度一般,准确。但是被墙了,国内无法正常访问。
- RSS.app:更新快,准确。但是只能抓取前几条内容,想要保留所有内容需付费升级账号。是否被墙倒是没试过。
试了一遍论坛/讨论组内大伙儿推荐的 RSS 生成服务提供商,没有完美地达到我的期望,每个都是差一点,只能靠自己了。
尝试二:手动制作静态文件
眼见外部服务不好使,于是乎我跑去看了看 RSS 的语法规范,尝试用最笨的方法:按照语法自己手动编写一份 XML 文档出来,给到读者去订阅。
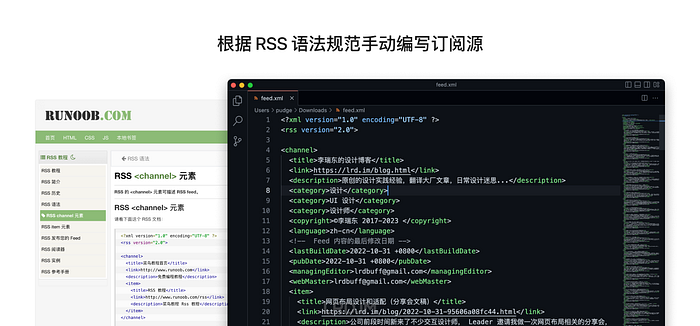
大费周章按 RSS 语法规范写完了 XML,传了两份用作测试,一份传在自己的阿里云轻应用服务器上,另一份传到了阿里云 OSS 里。之后用第三方阅读器订阅 RSS 链接。
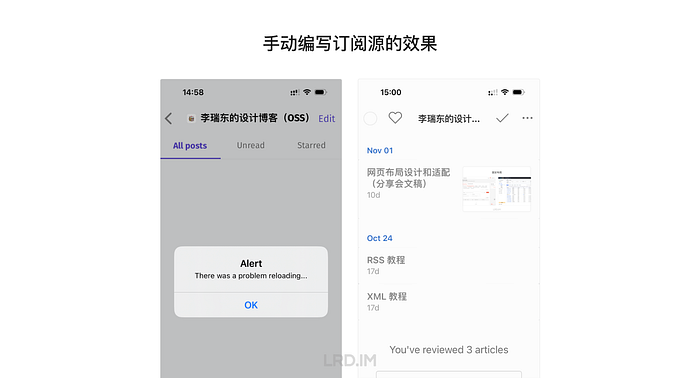
结果在阅读器里看到顺序错乱,时间异常,更新非常迟缓。刚开始我还以为这个笨方法能行得通,只是做起来比较麻烦,没想到仍然有这么多缺点。
最后一试:用 RSSHub 将自己网站生成为 RSS 源

了解 RSSHub
前两种方法试过都不能满足我的要求之后,我实在找不到一个好的思路或方向去实现,唯有在 V2EX 上发了个帖子请教下其他人。虽然帖子只有两个人回复,但足够启发我去解决问题了。

一楼回复建议我给 RSSHub 提个申请,让其他人写个规则来抓取我的网站,然后合并到 RSSHub 项目里,用该链接作为 RSS 的订阅链接。
后面我去了解了下 RSSHub,原来这是一个开源的 RSS 订阅源生成器,编写好规则(项目内称为脚本)后就能将内容按照 RSS 的语法生成一份订阅源,之后都可以用生成出来的链接在第三方阅读器上订阅和浏览。同时可以部署在自己的服务器里面,也能直接用 RSSHub 项目内别人预先编写好的规则,两者的效果是一样的。
粗浅了解下 RSSHub 的能力,以及也看了用该服务生成出来的订阅链接,功能上是能解决我的问题,但是时效性、准确度这些得自己部署完才能知道。
二楼回复认为静态的 XML 文件作为订阅源,会存在着不受我控制的缓存机制。于是乎我更坚定地认为应该尝试使用 RSSHub 的服务,毕竟这是动态生成,不是一个憨憨的静态文件。
安装 RSSHub
登录到服务器,由于我用的网站在阿里云轻服务器上搭建的,所以直接在网页里就能远程登录,其他服务器也能 ssh 登录后依次输入指令安装并运行 RSSHub。
git clone https://github.com/DIYgod/RSSHub.git
cd RSSHub
npm install
npm start成功安装并运行后,在浏览器访问 1200 端口应该能看到如下页面。

回到终端,设置 RSSHub 服务常驻(断开 ssh 链接后仍然保持服务);以及开机自启。
# 设置常驻
npm install pm2 -g
pm2 start lib/index.js# 设置开机自启
pm2 save
pm2 startup
这时可以访问几个 RSSHub 项目自带的路由,探索下其他有趣的 RSS 源。然后开始编写自己的脚本路由。
编写脚本路由
这一部分我的思路是参考文档的指引,并且在 RSSHub 项目内找到已有的脚本路由,找一份与自己网页结构类似的脚本,照葫芦画瓢捣鼓一份出来。
按文档的说法,/lib/router.js 里面记载了所有路由,即指明通过域名访问而指向的脚本。我先在里面创建一个路由,让其链接到之后创建的脚本。
# 添加路由
router.get('/feed', lazyloadRouteHandler('./routes/lrdim/blogs'));
其中 /feed 意思是我希望通过域名/feed 能够访问到我的 RSS 源,即 lrd.im/feed。后面的 ./routes/lrdim/blogs 意思是用前面的链接访问时,是链接到 /routes/lrdim/blogs.js 这个文件,用里面的规则生成 RSS 源。
然后到 /lib/routes 里面创建 lrdim 这个文件夹,并在里面创建 blog.js 这个文件,我们的抓取规则要写在里面。
由于我的网站是静态的 HTML 页面,所以我按照文档里的第二种方法,按照元素的标签和样式来抓取里面的数据。并且当时有参考了一个网页结构同样很简单的 RSSHub 内置源:十年之约。具体做法不在这详细说明了,主要按文档规范走就没啥问题,cheerio 语法也很直观容易理解。
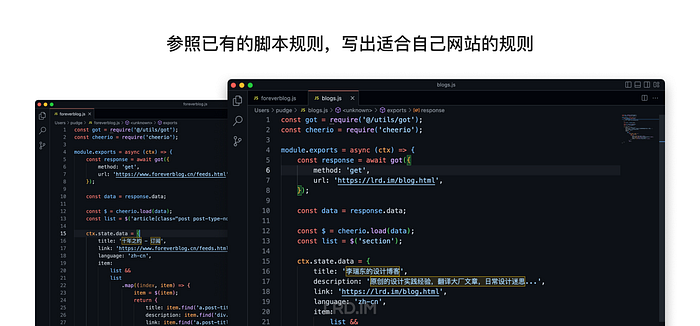
保存后过几分钟,已经能在 lrd.im:1200/feed 中访问生成的 RSS 源了。此时需检查下名称、描述、标题、摘要、日期等有没有问题。
注意:日期必须按照格式编写,不能出现非法内容。否则这条 item 不会出现在结果中。我是写成了 YYYY-MM-DD。
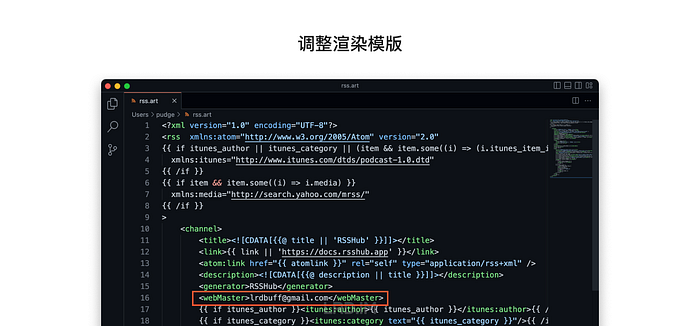
调整渲染模版
由于刚刚通过设置 RSSHub 脚本获取到的数据,会经过 rss.art 模版处理后再成为 RSS 订阅源,所以我们需要打开 /lib/views/rss.art 对渲染模版作出相应的调整,比如预设 <webMaster> 不符合预期,调整为我自己的邮箱。
设置代理
至此,我的 RSS 订阅源已经生成完毕,内容、格式等符合要求,剩下的只有域名还不大对劲。
截至到上面的步骤,我的 RSS 订阅源扔人家需要通过端口来访问:lrd.im:1200/feed。这个肯定是不能作为最终产物的,谁会把端口直接暴露出来,太丢人了。于是乎需要配置最后一步:设置代理。
我的服务器里安装了 nginx,打开 nginx/conf/nginx.conf 后配置代理,将 lrd.im/feed 指向 1200 端口的页面。
location /feed {
proxy_pass http://127.0.0.1:1200;
}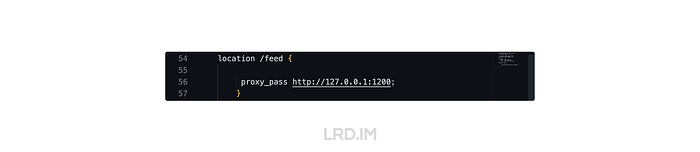
此时测试 lrd.im/feed,已经能正常访问经 RSSHub 生成的订阅源。
验收
拿订阅链接去各主流阅读器中试验,尝试搜索、添加此链接,并尝试增删改被抓取的网页内容,检查到确实能够及时更新,且不会信息错乱。
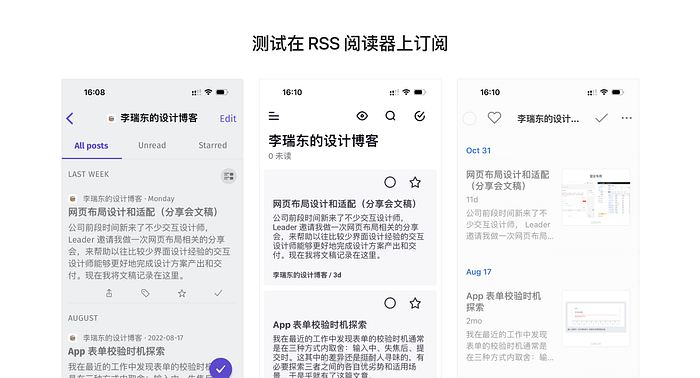
大功告成!奉上我的设计博客正式的 RSS 订阅链接:https://lrd.im/feed
将该链接复制到 RSS 阅读器上就能够及时获取我的最新设计博客了。阅读器的话看个人喜好,目前我觉得 Inoreader 和 Reeder 的体验都不错。
做多啲:在网站中曝光 RSS 订阅功能
费了这么大周章捣鼓的新功能,起码在我的网站里多多曝光才是。所以我顺手做了三件事。
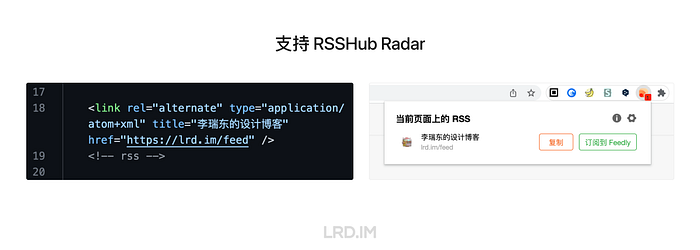
支持 RSSHub Radar
RSSHub 有一个浏览器插件叫 RSSHub Radar,用于探测网站上提供的 RSS,让读者能在浏览器的插件位置直接就能订阅,而不必在网页上费劲去找 RSS 订阅按钮。
支持该功能也不怎么复杂,我在所有页面的 <head> 处都添加了一条订阅地址,就能够被 RSSHub Radar 识别到。
博客页新功能提示
既然是我的博客内容的 RSS 源,那理所当然地应该在 lrd.im/blog.html 里添加一个稍微醒目一点的 Banner,提示到当前已经支持 RSS 啦!
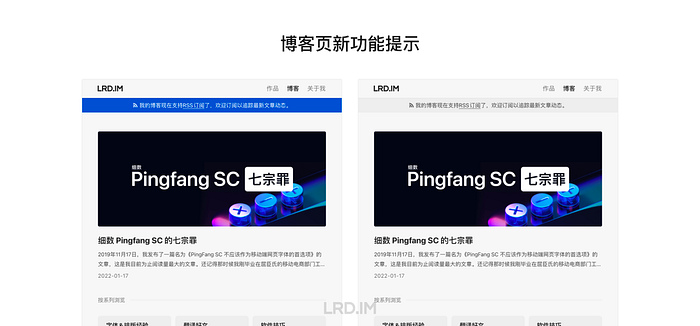
此处参考了 Instagram 和 Apple 的样式,高亮若干秒之后开始减弱对比,使其融入到页面中。用了 CSS 的 keyframe 来做。
博客详情页功能组
从 Google Analytics 处跟踪到的数据,挺多流量是来自直接的博客详情页,而不是先从列表页跳转到详情页。所以也为了增加在详情页的曝光,我在「作者信息」一行右侧新添加了几个按钮,分别是:复制文章链接、RSS 订阅、联系小东。
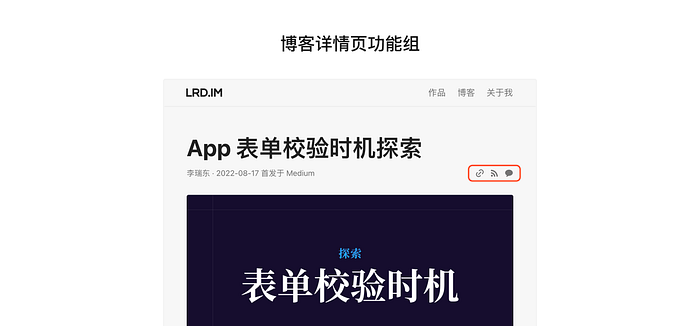
原本「复制文章链接」这个功能我是做成响应式设计,只在移动端尺寸下才能看到,但还是根据 GA 数据反馈,造访我的博客的流量中有至少 75% 是来自桌面端,所以我将这个功能开放了。
「RSS 订阅」功能点击后能直接跳转到 lrd.im/feed,后续的订阅操作懂得都懂。每篇文章都提供这个入口,极大提高曝光量。
「联系小东」的功能是点击后出现我的微信二维码。我的设计博客通常会输出我的观点和看法,而我的网站里面又没有评论的功能,所以我捣鼓了一个微信二维码上去,读者如果有东西想和我交流就能直接加我好友一起交流。
这些功能没做成悬停在左右两侧,原因是我不太想在读者阅读时有其他干扰项。
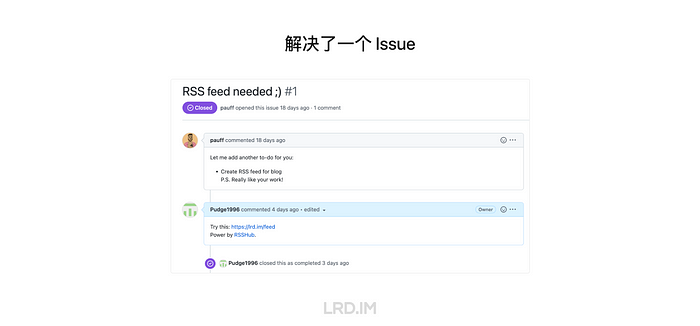
哦对了,还顺便 Close 了一个,也是目前唯一一个 Issue。
总结
给博客生成 RSS 订阅源这事虽然一直惦记了有大半年,但实际开始到最终呈现,历时一周左右,都是用下班时间和周末探索的。
又到了给自己挖坑的时间:后面关于博客订阅这块,我会做的几件事:
- 想办法将自己的 RSS 源链接提交到 RSSHub 项目下的博客分类;
- 研究主流的 RSS 阅读器抓取文章首图的规则。现在抓取的首图并非每次都符合我的预期,可能本身我的博客详情页构造需要作些许调整;
- 探索开拓邮箱订阅功能的必要性。目前 Medium 能够用邮箱订阅我的最新博客动态,在想是否需要用到 Revue 或竹白之类的自己捣鼓一个邮件订阅服务,内嵌到个人网站里面去。顾虑是担心这种平台的文本编辑器功能是否够完善,以及和 Medium 功能重复了。
完成了自己的一项执念,如释重负,舒坦开朗。但心里仍然藏了另一项执念,我惦记了有至少一两年了,仍待推进…
